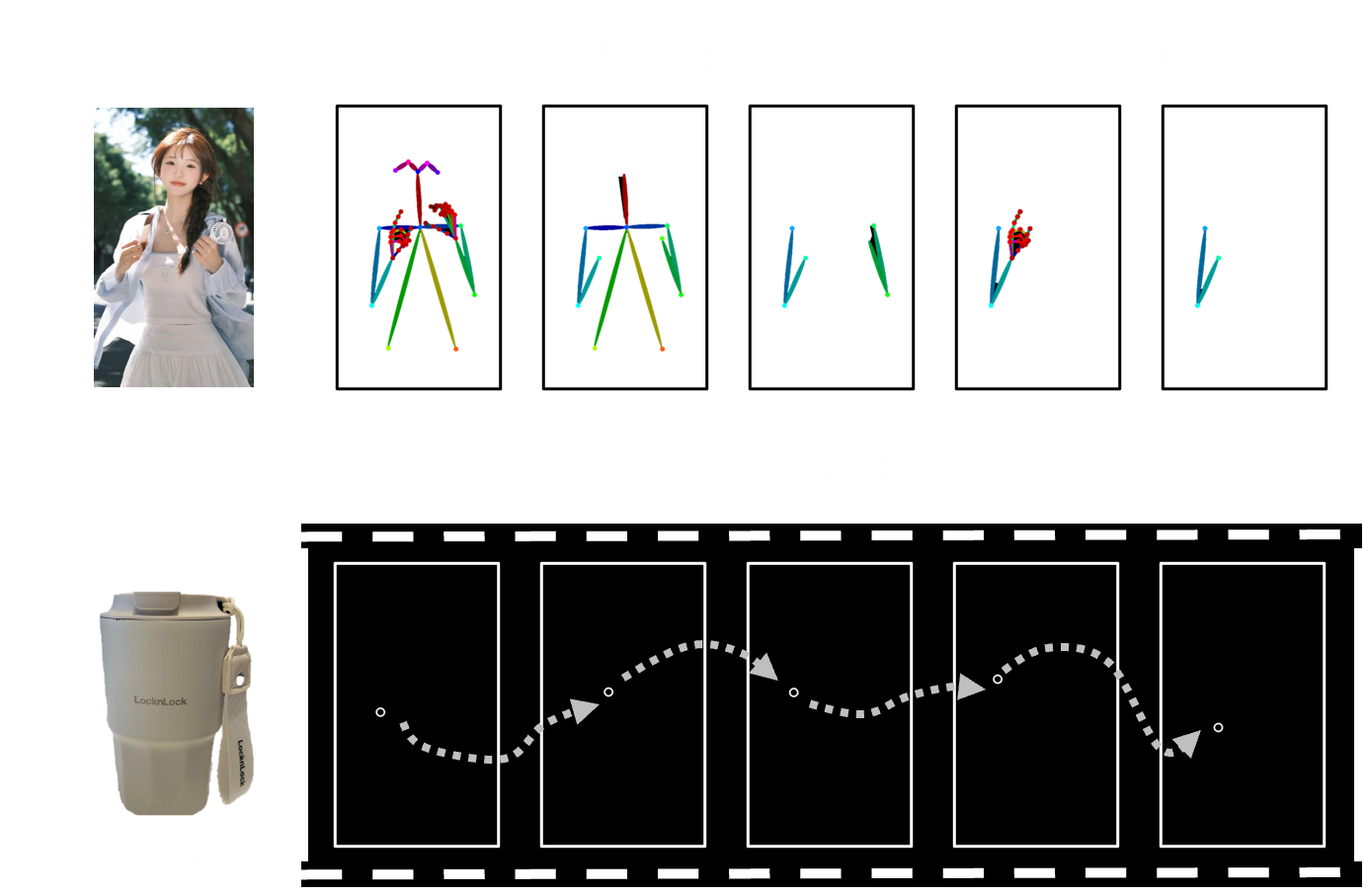
Weak Condition for HOI
We explore a weak HOI condition, where each component of the human pose can be optionally removed, and the object’s motion is a sequence of dots indicating the center points of its trajectory.
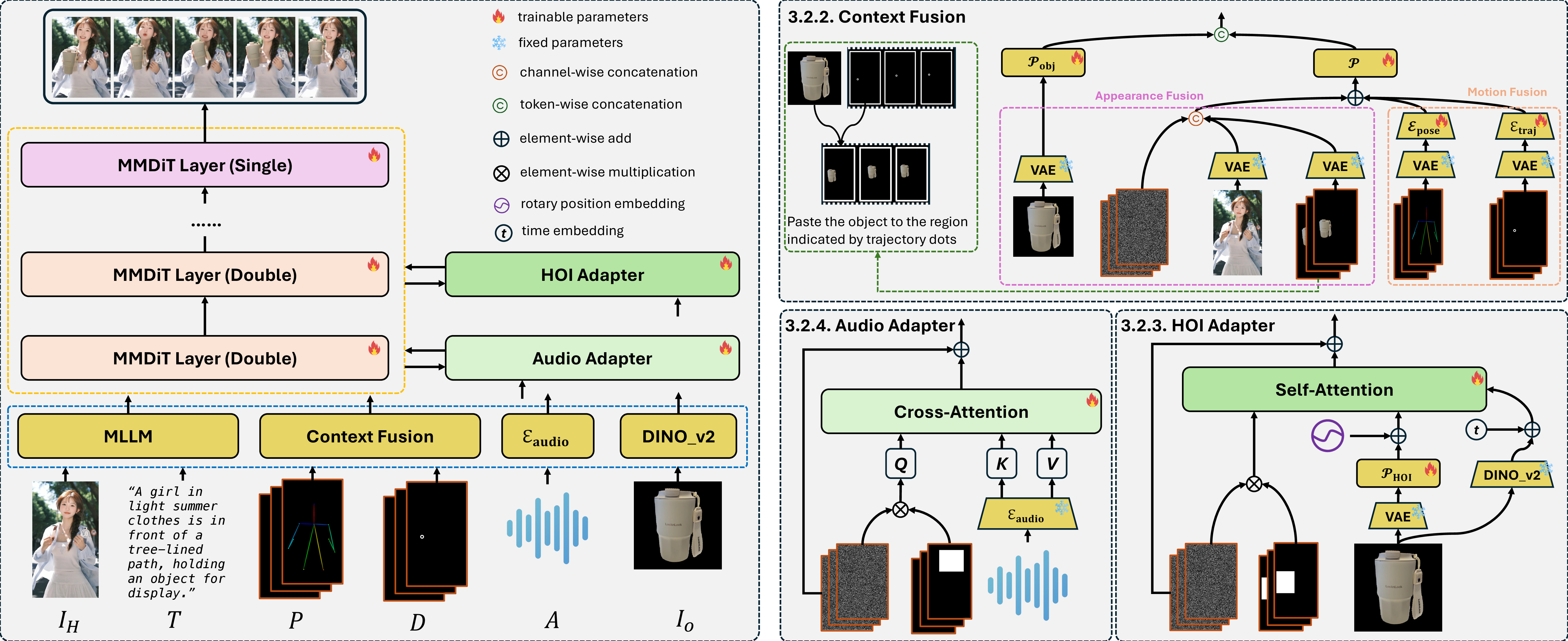
To address key limitations in human-object interaction (HOI) video generation—specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility—we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface.


We provide an interactive web demo that allows users to intuitively define human-object interactions by manually dragging the human pose and object position. This interactive tool grants the model adaptive freedom to resolve ambiguities, bridging the gap between artistic intent and generative feasibility.